|
Source: Gartner Research
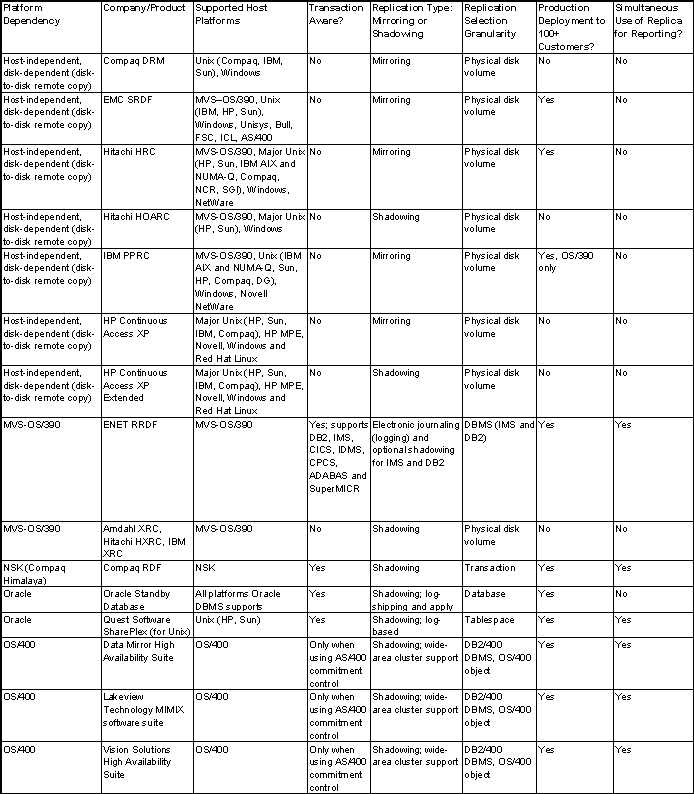
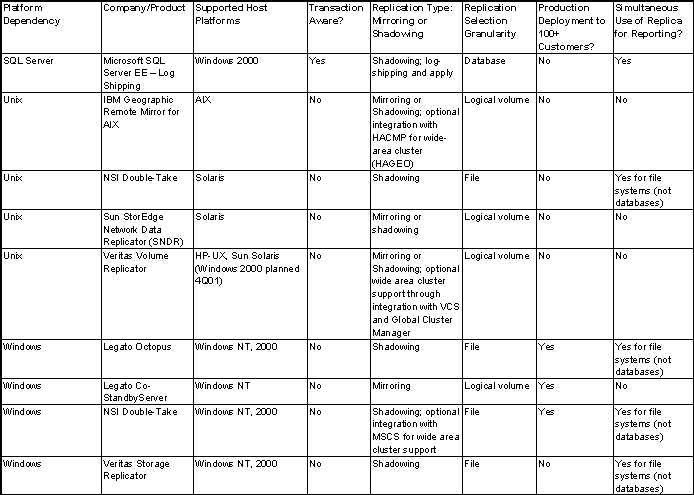
Host-based disk block replication alternatives, such as IBM's
Geographic Remote Mirror for AIX and Veritas Software's Volume Replicator,
are fairly new to the market and have not made significant market inroads
yet. However, as they mature, they offer the potential for a less
expensive solution to replicate all enterprise data, regardless of the
disk platform chosen. For Windows environments, file-based replication
solutions from NSI Software and Legato Systems have garnered a significant
number of installations, and Veritas has recently entered this market.
Also popular, and generally less costly, are log-based database
replication solutions. These include solutions from DataMirror, Lakeview
Technology, Microsoft, Oracle, Quest Software and Vision Solutions. Note
that traditional trigger-based native DBMS replication is generally not
appropriate for disaster recovery because of high system and
administrative overhead on the primary site.
When making replication decisions, enterprises must first evaluate
recovery point objectives. If some number of minutes (typically between
five and 60 minutes) of lost transactions is acceptable, an asynchronous
solution will probably provide a more cost-effective solution while still
offering fast recovery. Where a small number of transactions can be lost
(e.g., those uncommitted at the primary system and the secondary system),
synchronous mirroring must be deployed. Other product evaluation criteria
should be platform support, integration with other complementary products
such as clustering technology, cost, speed of deployment, performance
impact, product completeness and manageability.
Finally, enterprises must keep in mind that the replication solutions
are just one part of the disaster recovery plan. To ensure confidence in
the recovery capability of the enterprise, frequent testing of these plans
is vital (one to four times a year, depending on the amount of change to
the applications and infrastructure). This includes testing of replication
solutions under various failure/disaster scenarios to ensure appropriate
recovery behavior of databases, file systems and applications.
Definition of Terms
Transaction-Aware Replication: Transaction-aware replication
offers transaction-level replication, typically by electronically
transmitting database or file changes (e.g., through logs) to the
secondary site and applying those changes to a replica image. The primary
advantage of this approach is that the replication method understands
units of work (e.g., transactions) and has a greater potential for data
integrity (via transaction roll-forward/back), although data integrity is
not guaranteed.
Mirroring or Shadowing: Shadowing maintains a replica of
databases and/or file systems, typically by continuously capturing changes
and applying them at the recovery site. Shadowing is an asynchronous
process, thus requiring less network bandwidth than synchronous mirroring.
Recovery time objectives (RTOs) are significantly reduced (generally
between one and eight hours, depending on the lag time for applying logs),
while recovery point objectives (RPOs) are as up-to-date as the last
receipt and apply of the logs. Mirroring maintains a replica of
databases and/or file systems by applying changes at the secondary site in
lock step with or synchronous to changes at the primary site. As a result,
RTOs can be reduced to 20 minutes to several hours, while RPOs are reduced
only to the loss of uncommitted work. Because it is synchronous, mirroring
requires significantly greater network bandwidth than shadowing. Too
little bandwidth and/or high latencies will degrade the performance of the
production system.
Deployed to 100 or More Sites? The number of production
deployments will aid enterprises in understanding the maturity of the
solution. In general, the fewer the production deployments, the higher the
degree of risk associated with implementing the solution.
Use Replica for Reporting? Most data replication solutions
supporting disaster recovery do not enable inquiry/reporting of the
replica at the secondary site (most require a third copy to be made for
reporting). Using the replica for reporting offloads production workloads
for horizontal scalability and achieves better resource utilization of the
disaster recovery configuration (e.g., it reduces the total cost of
ownership of a disaster recovery
configuration). |